Transformer的诞生背景#
传统的模型只能一次处理一个词,比如RNN、LSTM,他们:
- 无法并行计算:必须一个时间步一个时间步地算;序列越长,训练越慢
- 长程依赖问题:RNN 理论上能记住过去所有信息,但实际上梯度会消失或爆炸
- 信息压缩严重、难以捕捉全局关系:RNN 的隐藏状态 \(h_t\) 是一个固定长度的向量,但它要“压缩”从第 1 个到第 t 个所有词的信息,导致信息丢失,并且无法建模任意两个词之间的全局依赖。
而Transformer的出现改变了这一状况,它直接抛弃了循环结构,提出了一个全并行的注意力机制模型。他可以一次性看到全文,可以反复回看,找到关键句,还能从多角度理解句子。
Transformer整体结构#
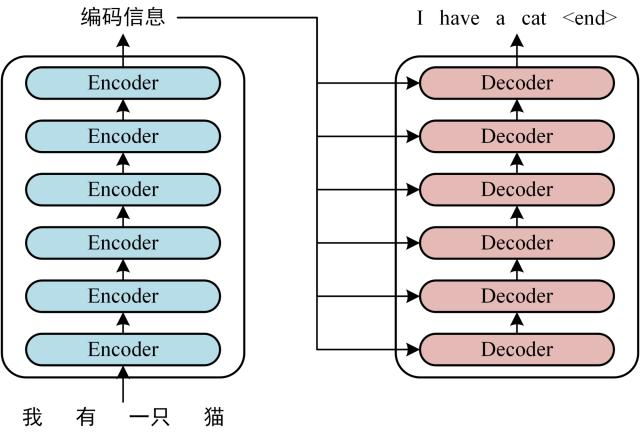
Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
第一步#
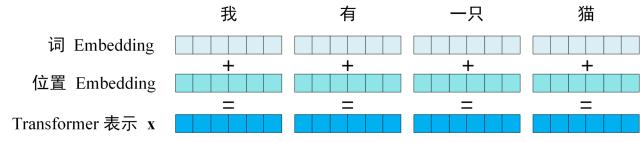
获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。
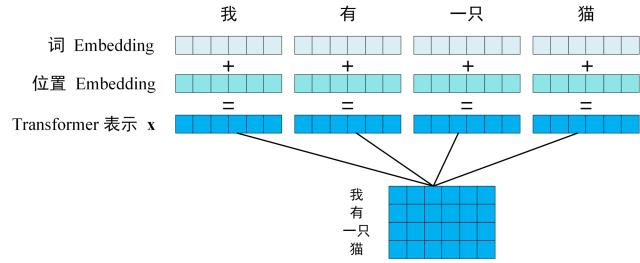
第二步#
将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图。单词向量矩阵用\(\mathbf{X}_{n \times d}\)表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
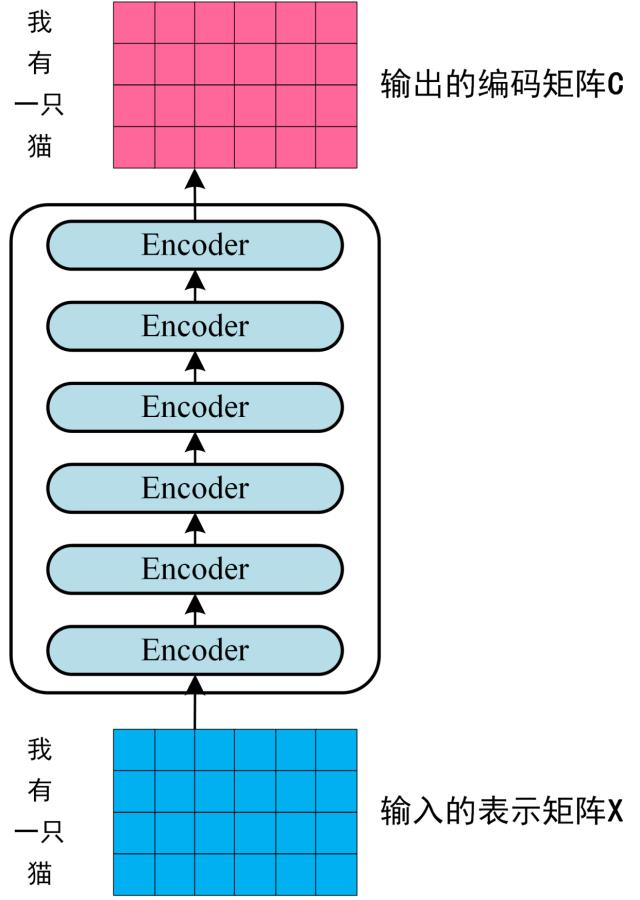
第三步#
将 Encoder 输出的编码信息矩阵 C 传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
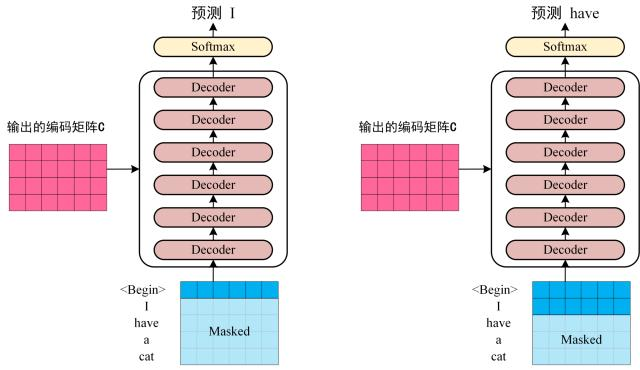
上图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 “<Begin>",预测第一个单词 “I”;然后输入翻译开始符 “<Begin>” 和单词 “I”,预测单词 “have”,以此类推。
这是 Transformer 使用时候的大致流程,细节将在下方娓娓道来。
Transformer的输入#
- 单词Embedding:有很多种获取方式,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
- 位置Embedding:由于不采用RNN结构,而是使用全局信息,Transformer不能利用单词的顺序信息,所以使用位置Embedding 保存单词在序列中的相对或绝对位置。
位置 Embedding 用 PE表示,PE 的维度与单词 Embedding 是一样的。PE可以通过训练得到,也可以使用某种公式计算得到。在 Transformer中采用了后者,计算公式如下: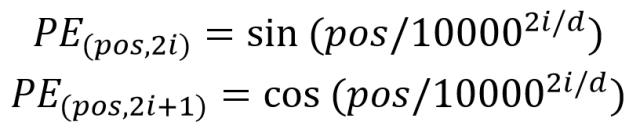
- 使 PE 能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
- 可以让模型容易地计算出相对位置,对于固定长度的间距 k,PE(pos+k) 可以用 PE(pos) 计算得到。因为 Sin(A+B) = Sin(A)Cos(B) + Cos(A)Sin(B), Cos(A+B) = Cos(A)Cos(B) - Sin(A)Sin(B)。
位置编码是给 Transformer “加入顺序感”的方法。 它用一组不同频率的正弦和余弦波,为每个词生成唯一的位置向量, 让模型在并行处理时也能知道词与词的先后关系。
将单词的词 Embedding 和位置 Embedding 相加,就可以得到单词的表示向量 x,x 就是 Transformer 的输入。
Self-Attention(自注意力机制)#
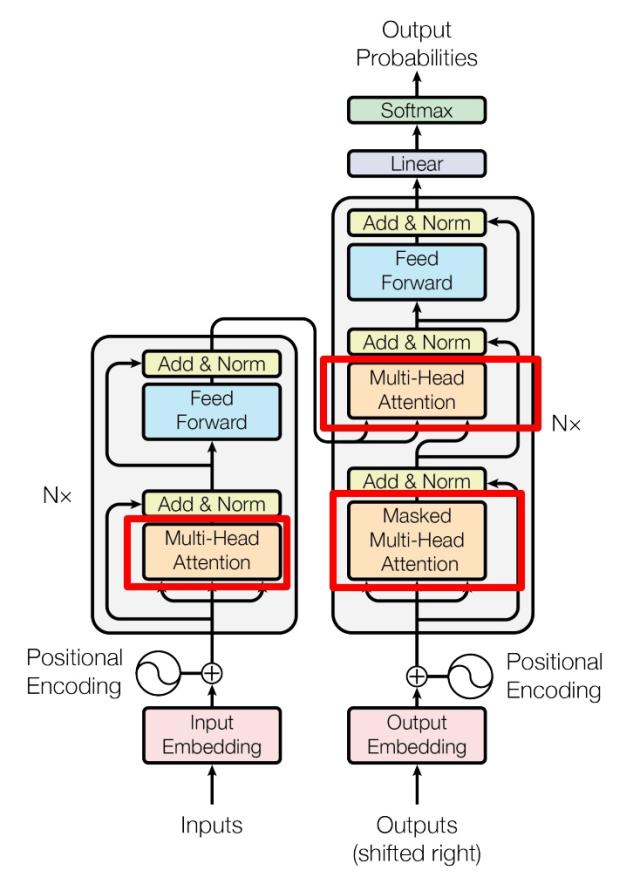
- 左侧为 Encoder block,右侧为 Decoder block
- 红色框中的Multi-Head Attention由多个 Self-Attention组成
- Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)
- Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化
Self-Attention内部结构#
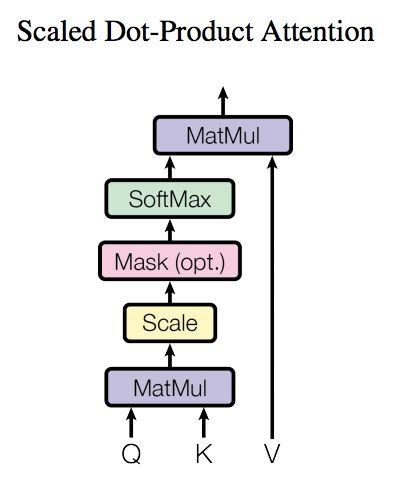
Self-Attention 在计算的时候需要用到矩阵Q(查询),K(键值),V(值)
在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的。
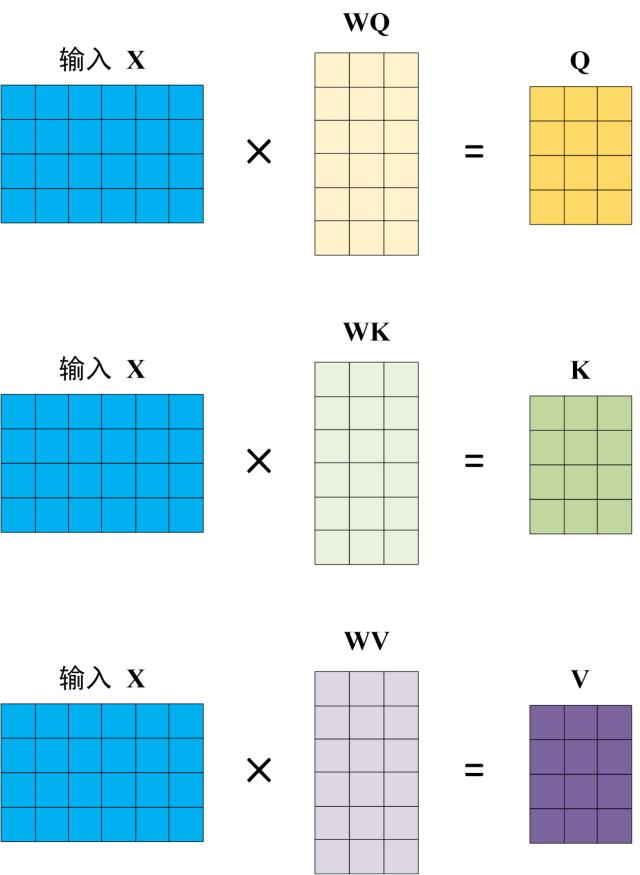
Q,K,V的计算#
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ, WK, WV计算得到Q, K, V。
注意 X, Q, K, V 的每一行都表示一个单词。
Self-Attention 的输出#

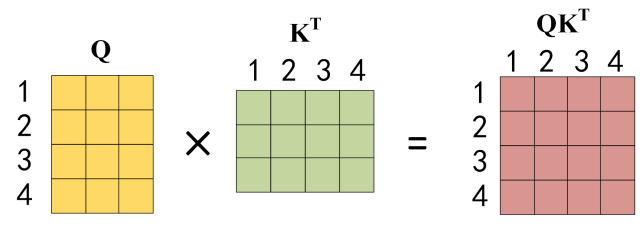
公式中计算矩阵Q和K每一行向量的内积,为了防止内积过大,因此除以 \(d_k\) 的平方根。Q乘以K的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。下图为Q乘以 \(K^T\) ,1234 表示的是句子中的单词。
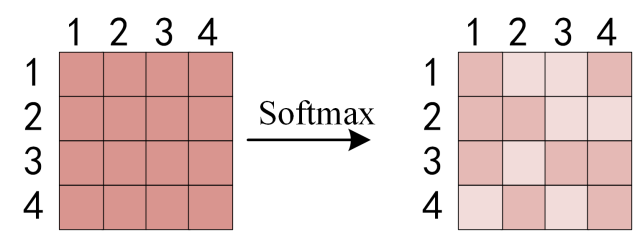
得到 \(QK^T\) 之后,使用 Softmax 计算每一个单词对于其他单词的 attention 系数,公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1.
得到 Softmax 矩阵之后可以和V相乘,得到最终的输出Z。
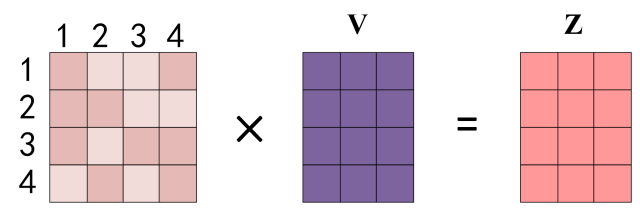
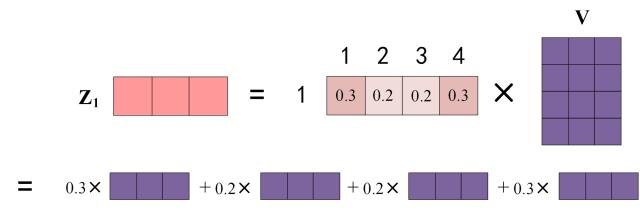
上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数,最终单词 1 的输出 \(Z_1\) 等于所有单词 i 的值 \(V_i\) 根据 attention 系数的比例加在一起得到,如下图所示:
从语义角度理解:#
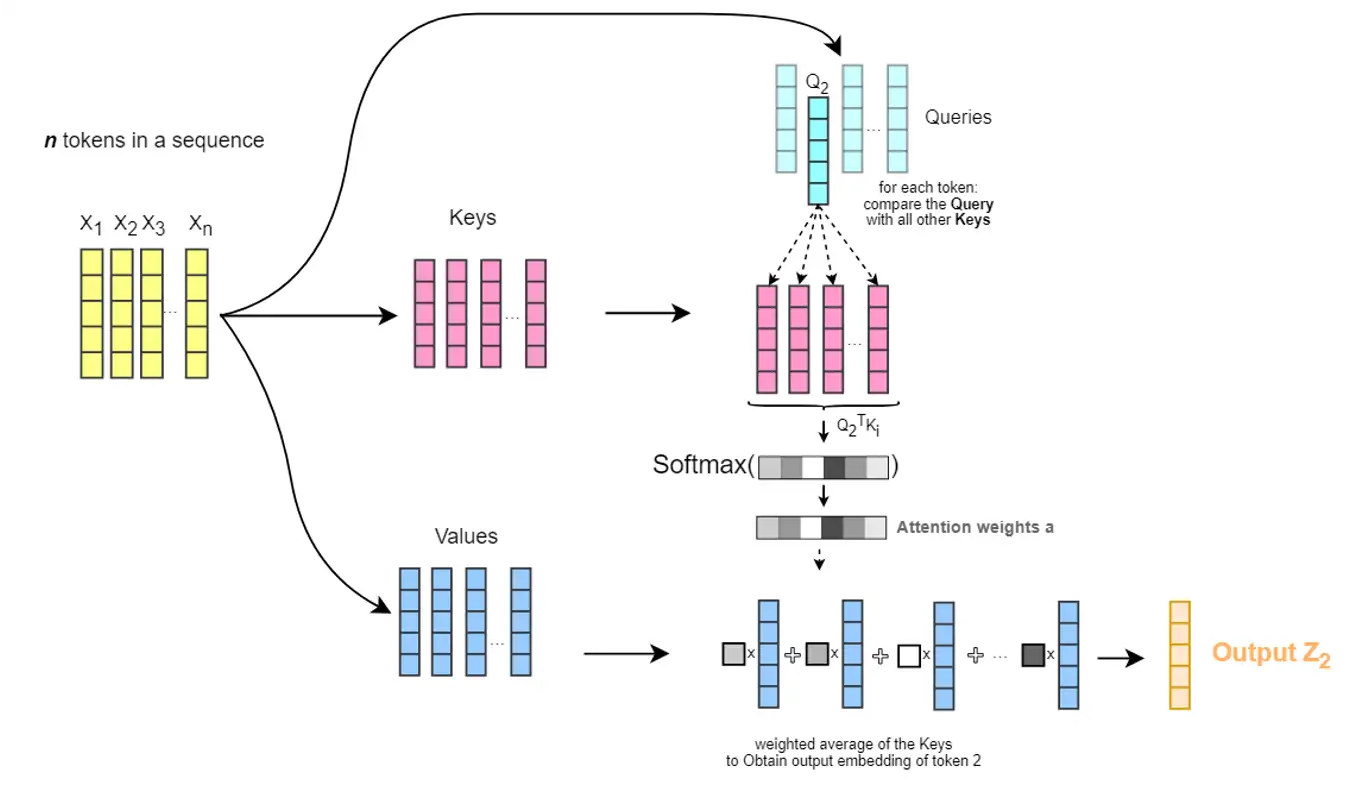
比如这样一句话:“He booked a room at a hotel.”。我们对其中“booked”这个单词(实际上是 token)做 Attention 机制。“booked”会对“He booked a room at a hotel.”这句话中所有的 token ,包括“booked”自己,都做一遍点乘,然后做 Softmax 。再然后,Softmax 后的结果与“He booked a room at a hotel.”转换成的 V 向量相乘,得到加权后的变换结果:0.55*booked+0.15*room+0.3*hotel=booked,即“booked”这个单词可以用“0.55*booked+0.15*room+0.3*hotel” 这样一个复杂的单词来表示(把“0.55*booked+0.15*room+0.3*hotel”想象成一个单词,便能轻松理解这样表示的意义),见下图:
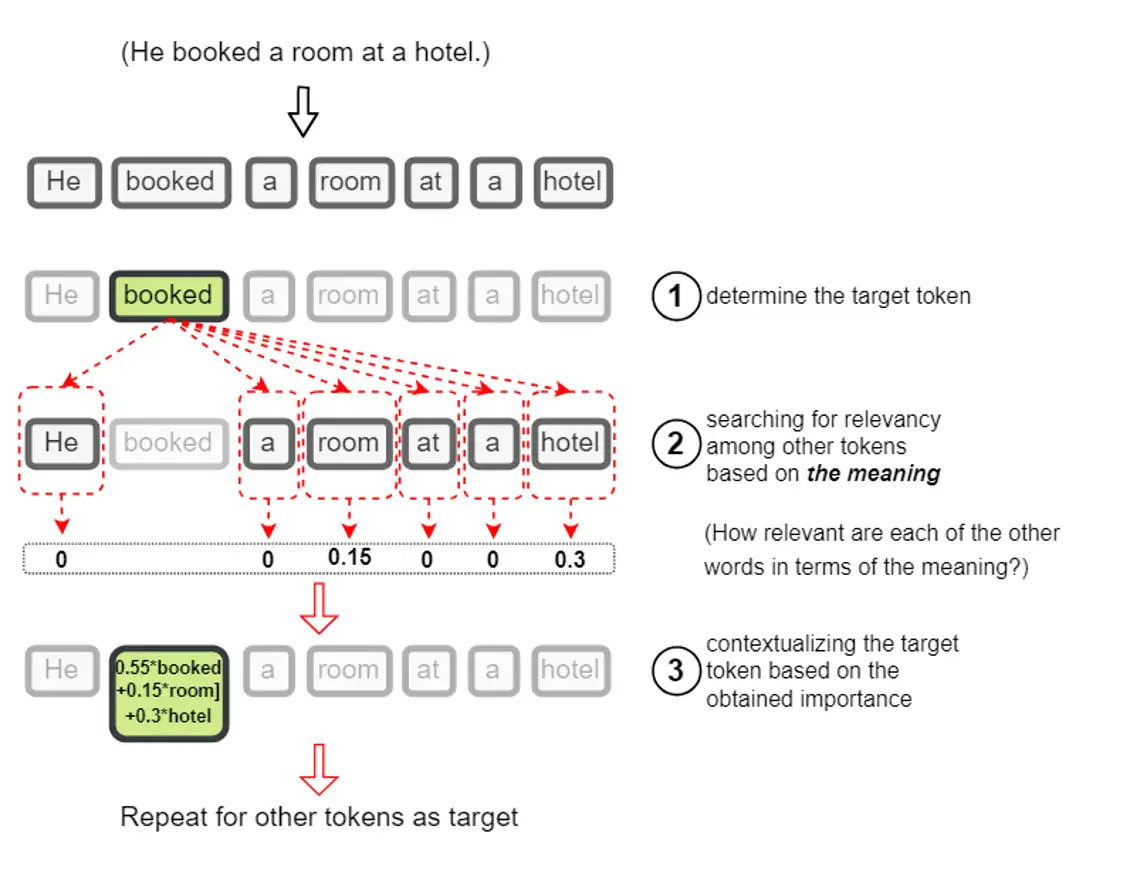
从中可以看出“booked”在全句中与“hotel”关联度最大,其次是“room”。所以“booked”这个单词也可以理解为“hotel-room-booked”。这便把“booked”在这句话中的本质通过“变形”给体现出来了。“booked”本身并没有变,而是通过“变形”展示出了另外一种变体状态“hotel-room-booked”。
一张图总结Multi-Attention机制之间的逻辑关系:
Multi-Head Attention#
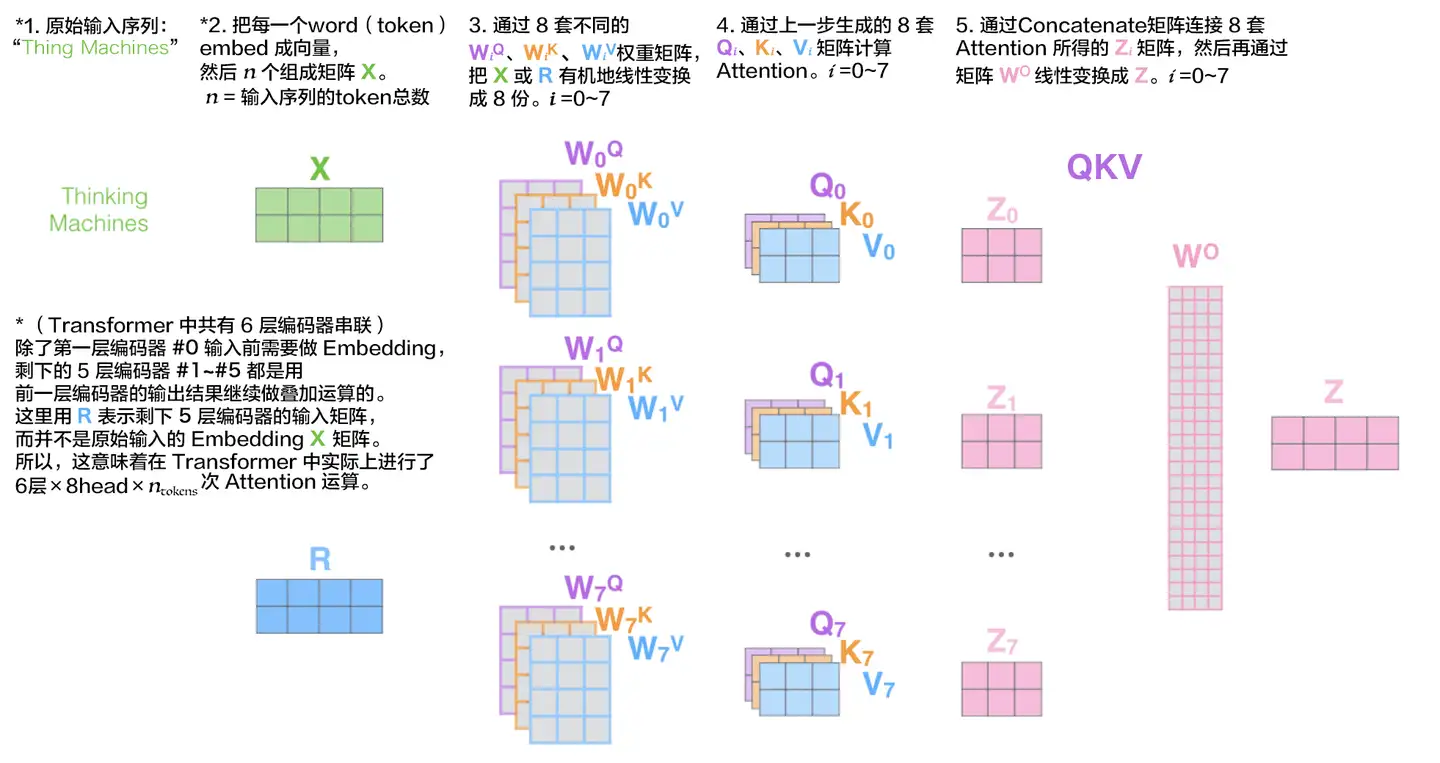
Multi-Head Attention由多个Self-Attention组合而成
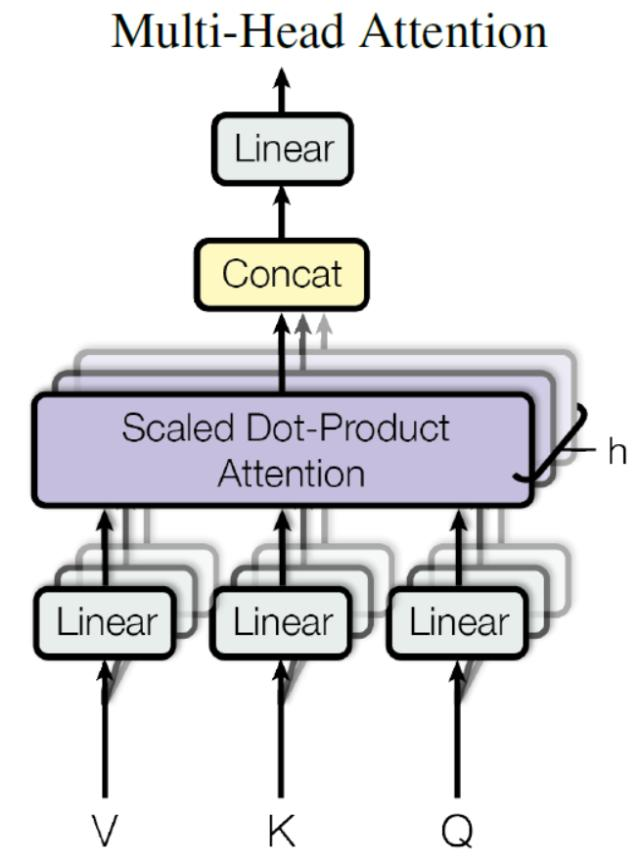
首先将输入X分别传递到 h 个不同的 Self-Attention 中,计算得到 h 个输出矩阵Z。
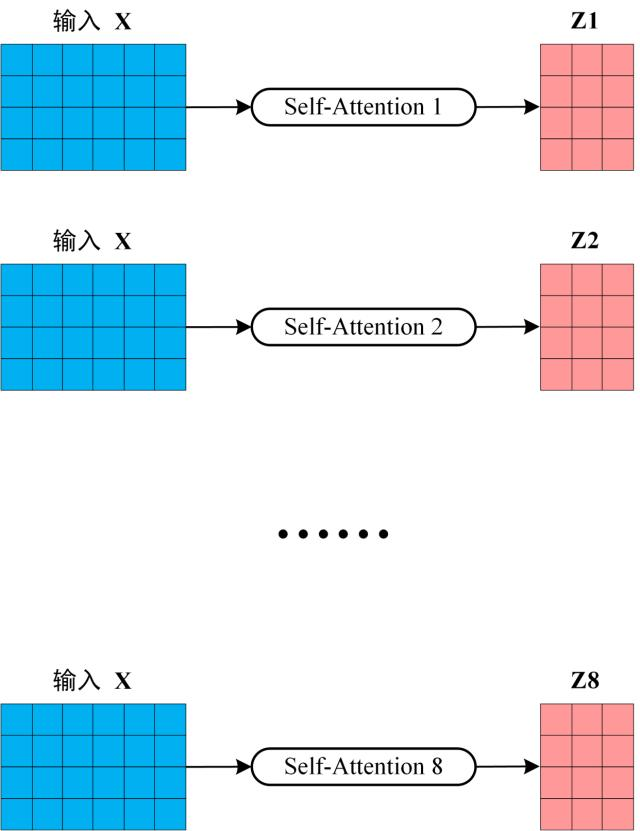
得到 8 个输出矩阵 \(Z_1\) 到 \(Z_8\) 之后,Multi-Head Attention 将它们拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z。
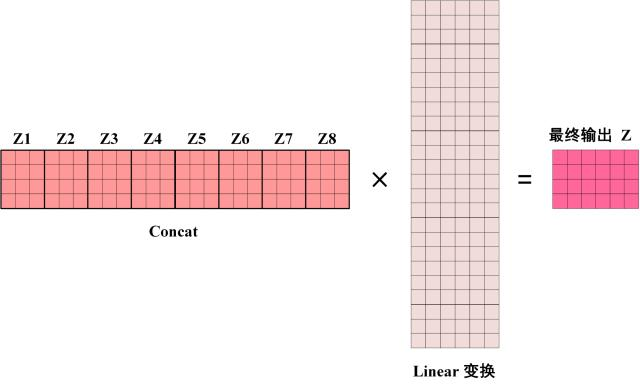
Multi-Head Attention 输出的矩阵Z与其输入的矩阵X的维度是一样的
以上的Multi-Head Attention似乎稍有偏差,实际步骤如下:

通过把 Embedding 向量线性变幻成 8 个 1/8 的向量再分别去做 Attention 机制运算,这其实在本质上并不会耽误每个 token 的语义表达,而只是细分出了不同的语义子空间,即不同类型的细分语义逻辑而已,Attention 机制运算起来将更细腻精准、更有针对性。
Encoder结构#
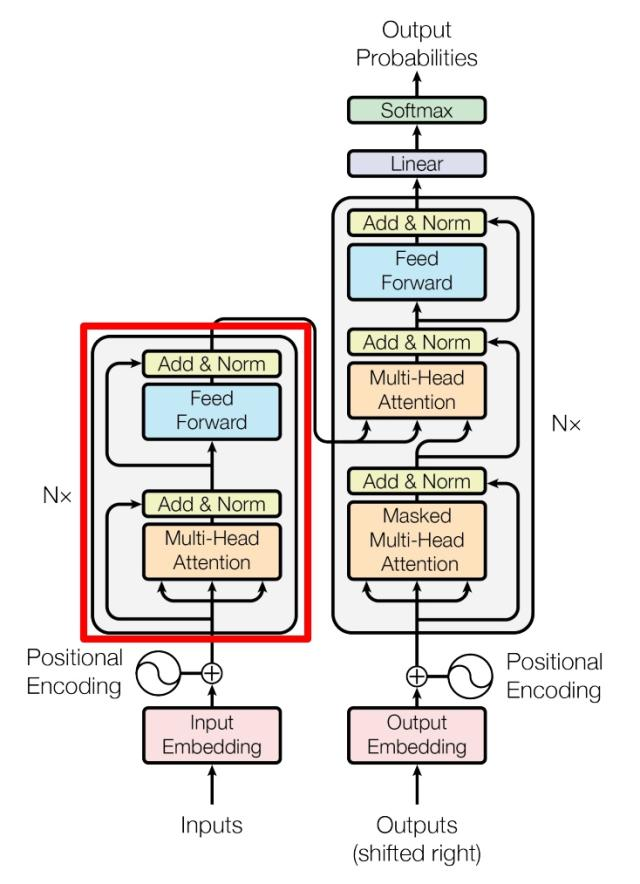
Transformer 的 Encoder block 结构,可以看到是由 Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm 组成的。
Add & Norm#
Add & Norm 层由 Add 和 Norm 两部分组成,其计算公式如下:

其中 X表示 Multi-Head Attention 或者 Feed Forward 的输入,MultiHeadAttention(X) 和 FeedForward(X) 表示输出 (输出与输入 X 维度是一样的,所以可以相加)。
Add指 X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到:

Norm指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
补充:Layer Normalization#
BN 的诞生背景
在深度学习训练中,有一个经典问题叫做内部协变量偏移(Internal Covariate Shift):
- 网络每一层的输入分布会随着前一层参数更新而不断变化。
- 这就像训练目标一直在移动,导致每一层都要不断适应新的分布,训练会更困难,通常需要更小学习率和更谨慎的初始化。
Batch Normalization(BN)因此被提出:它在一个 batch 的样本之间,对每个神经元激活做归一化。
但 BN 在序列建模里有几个明显问题:
- 对 batch size 敏感:小 batch 下统计量估计不稳定,因为统计量估计不准确。
- 不适用于变长序列:在 RNN 或 Transformer 中,每个时间步的 BN 是独立的,处理变长序列时很麻烦。
比如输入批次
X的维度是[batch_size, sequence_length, feature_size]例如[2, 3, 4]说明有两个句子(样本),每个句子三个单词(时间步),每个单词有四维特征 BN会认为有3 * 4 = 12个独立的“神经元”,并计算它们的均值和方差 但假设第二个句子实际只有两个单词,为组成一个批次用0填充到最大长度3,假设使用BN,在“第三个时间步”计算均值方差时就会将原本有意义的值与填充的0混在一起,导致严重的统计偏差。 - 训练与推理不一致:3. 推理时依赖于移动平均的全局统计量,这有时会引入偏差。 训练时BN会实时计算每个小批次的均值和方差,并用它们来归一化数据。 但同时,BN会维护两个全局可训练的变量,叫做“移动平均值”: \[全局均值 = momentum * 旧全局均值 + (1 - momentum) * 当前批次均值\] \[全局方差 = momentum * 旧全局方差 + (1 - momentum) * 当前批次方差\] 这个“全局均值/方差”在训练过程中不断被更新,以期望它能逐渐逼近整个训练数据集的真实分布。 但推理时可能只使用一个样本,因此只能使用在训练阶段最终得到的那个“全局均值”和“全局方差”,可能会引入偏差。
为什么要有 LN LN 在 Transformer 中能有效规避 BN 的问题。核心思想是:
不再在一个 Batch 的样本之间做归一化,而是在一个样本内部、一个层的所有神经元之间做归一化。
在每个 token 的特征维度上,把该 token 的激活值“标准化到均值≈0、方差≈1”(再学习一个线性缩放与平移),从而:
- 让各层看到尺度更一致的输入信号
- 让学习率和初始化更鲁棒
- 让训练更稳定、收敛更快,深层网络更容易训练
BN 和 LN 的直观对比
假设我们有一个全连接层,输入是一个向量 x = [x1, x2, x3],输出是 h = [h1, h2, h3, h4](有 4 个神经元)。
- Batch Norm 的做法是:对于 Batch 中所有样本的
h1,计算均值和方差,然后归一化。对h2,h3,h4做同样的事。它归一化的维度是 [Batch]。 - Layer Norm 的做法是:对于单个样本,计算它自己的
h = [h1, h2, h3, h4]这个向量的均值和方差,然后用这个均值和方差来归一化这个向量本身。它归一化的维度是[Hidden_Size]。
数学定义 设某层输入某个 token 的向量为 \(x \in \mathbb{R}^{d}\)(\(d\) 为隐藏维度)。
对该 token 的特征维度计算均值与方差:
$$ \mu=\frac{1}{d}\sum_{i=1}^{d}x_i,\quad \sigma^2=\frac{1}{d}\sum_{i=1}^{d}(x_i-\mu)^2 $$标准化并做线性变换:
$$ \hat{x}_i=\frac{x_i-\mu}{\sqrt{\sigma^2+\varepsilon}},\quad y_i=\gamma_i\hat{x}_i+\beta_i $$其中:
- \(\varepsilon\):数值稳定项(如 \(1\times10^{-5}\))
- \(\gamma,\beta \in \mathbb{R}^{d}\):可学习逐维缩放/平移参数
注意:LN 的统计是 per-sample-per-position,不依赖 batch 大小。
LN 放在哪
- Post-LN(原始 Transformer):\(y=\mathrm{LayerNorm}(x+F(x))\)。早期常见,但深层训练稳定性较弱(随深度增大梯度更难传播)。
- Pre-LN(现主流,如 BERT/GPT/ViT):\(y=x+F(\mathrm{LayerNorm}(x))\)。梯度可更顺畅穿过残差主干,通常更稳、更易扩展到深层。
Feed Forward#
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下。
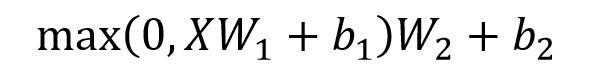
X是输入,Feed Forward 最终得到的输出矩阵的维度与X一致。
组成 Encoder#
Encoder block 接收输入矩阵\(\text{X}_{(n \times d)}\),并输出一个矩阵\(\text{O}_{(n \times d)}\)。通过多个 Encoder block 叠加就可以组成 Encoder。
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是编码信息矩阵 C,这一矩阵后续会用到 Decoder 中。
Decoder 结构#
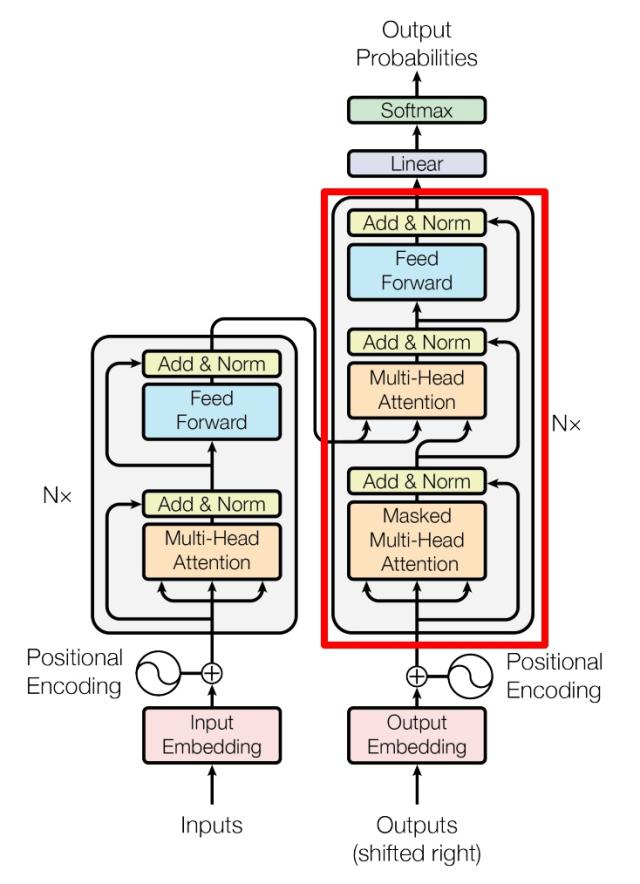
- 包含两个 Multi-Head Attention 层。
- 第一个 Multi-Head Attention 层采用了 Masked 操作。
- 第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
- 最后有一个 Softmax 层计算下一个翻译单词的概率。
第一个 Multi-Head Attention#
第一个Multi-Head Attention采用了Masked操作,因为在翻译过程中是按顺序翻译的。
通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。
下面以 “我有一只猫” 翻译成 “I have a cat” 为例:
在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入 “<Begin>” 预测出第一个单词为 “I”,然后根据输入 “<Begin> I” 预测下一个单词 “have”。

Decoder 可以在训练的过程中使用 Teacher Forcing 并且并行化训练,即将正确的单词序列 (<Begin> I have a cat) 和对应输出 (I have a cat <end>) 传递到 Decoder。那么在预测第 i 个输出时,就要将第 i+1 之后的单词掩盖住,注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的,下面用 0 1 2 3 4 5 分别表示 “<Begin> I have a cat <end>"。
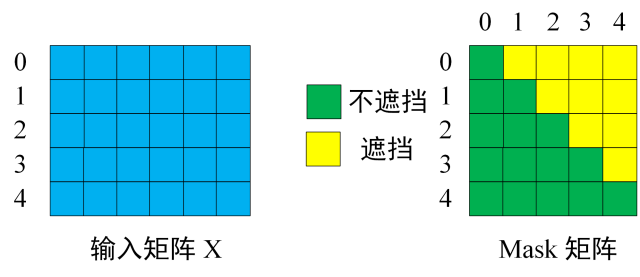
- 第一步:是 Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 “<Begin> I have a cat” (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。
Attention 计算中有:
$$ \text{scores} = \frac{QK^{T}}{\sqrt{d_{k}}} $$(形状是 [seq_len, seq_len])
然后加上 mask:
$$ scores = scores + mask $$其中:
- mask 的形状同样是 [seq_len, seq_len];
- 对不遮挡的位置 → mask = 0;
- 对遮挡的位置 → mask = -∞(或一个非常大的负数,比如 -1e9)。
最后做 softmax:
$$ \text{attention} = \text{softmax(scores)} $$由于 softmax(–∞) ≈ 0,
被遮挡的部分注意力权重几乎为 0,不会被关注。
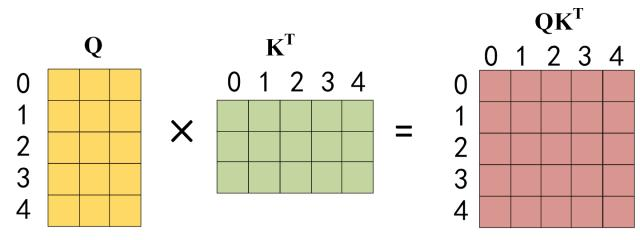
- 第二步:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵X计算得到Q,K,V矩阵。然后计算Q和 K^T 的乘积 QK^T
- 第三步:在得到 QK^T 之后需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:
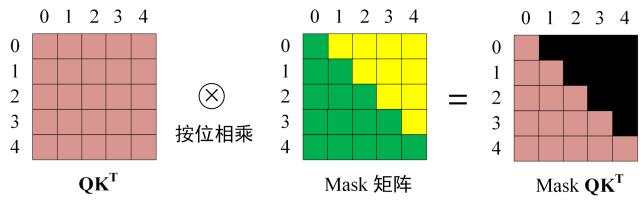
得到 Mask QK^T 之后在 Mask QK^T 上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。
- 第四步:使用 Mask QK^T 与矩阵 V相乘,得到输出 Z,则单词 1 的输出向量 是只包含单词 1 信息的。
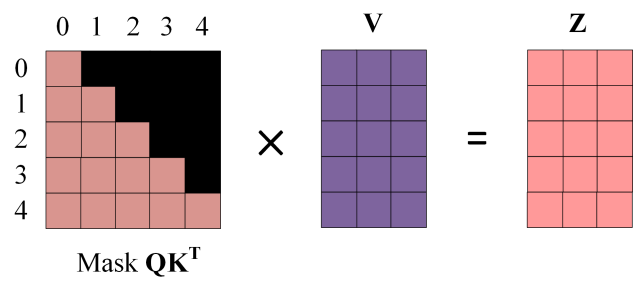
- 第五步:通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵 \(Z_i\) ,然后和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出 \(Z_i\) 然后计算得到第一个 Multi-Head Attention 的输出Z,Z与输入X维度一样。
第二个 Multi-Head Attention#
其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
根据 Encoder 的输出 C 计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q (如果是第一个 Decoder block 则使用输入矩阵 X 进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
Softmax 预测输出单词#
Decoder block 最后的部分是利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出 Z,因为 Mask 的存在,使得单词 0 的输出 \(Z_0\) 只包含单词 0 的信息,如下:
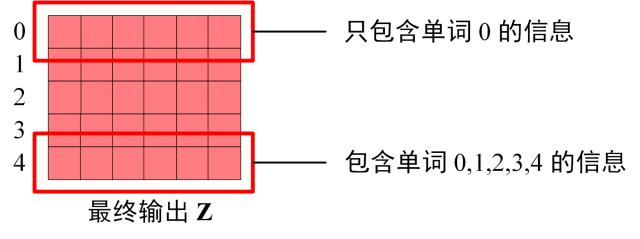
Softmax 根据输出矩阵的每一行预测下一个单词:
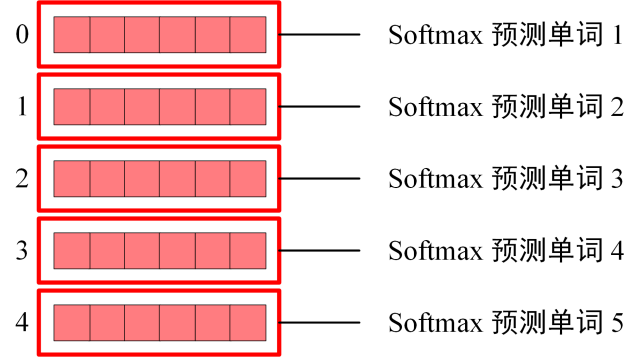
这就是 Decoder block 的定义,与 Encoder 一样,Decoder 是由多个 Decoder block 组合而成。
感觉以上讲的有些不清楚,tranformer的训练和推理过程对应的图也是不一样的
Transformer 能并行训练,是因为训练阶段一次性输入“右移后的目标句子”,同时计算所有位置的 z_i,即训练阶段一次性输出所有预测,正如上图所示。
而推理阶段必须自回归生成,只能一步步用最新的 z 来预测下一个词,所以每次循环都会生成一个新的Z,模型只用最下面那一行(最新时间步)来生成下一个词
至于“Softmax 根据输出矩阵的每一行预测下一个单词”是怎么实现的:
- 第一步:将最后一个decoder的输出,通过一个linear层,将向量维度转换为词表大小。
- 第二步:将linear层的输出,通过一个softmax,将每个词的可能性概率化。
也就是说,转换成词表大小的是linear层,softmax仅仅是概率化
| 阶段 | 输入是什么 | Mask 做什么 | 计算结果 | 能否并行 |
|---|---|---|---|---|
| 训练阶段 (Teacher Forcing) | 整个目标句子右移:[BOS] 我爱你 | 遮挡未来位置(不能看第 i+1 个词) | 一次计算得到所有 (z_0, z_1, z_2, z_3) | ✅ 可以并行(每个位置独立算) |
| 推理阶段 (Autoregressive Inference) | 当前已生成的部分:[BOS] 我爱 | 仍遮挡未来 | 计算新的 (Z),取最后一行 (z_t) | ❌ 只能串行(逐词生成) |
Transformer 总结#
- Transformer 与 RNN 不同,可以比较好地并行训练。
- Transformer 本身是不能利用单词的顺序信息的,因此需要在输入中添加位置 Embedding,否则 Transformer 就是一个词袋模型了。
- Transformer 的重点是 Self-Attention 结构,其中用到的 Q, K, V矩阵通过输出进行线性变换得到。
- Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。